
 Deutsch
Deutsch Dansk
Dansk Svenska
Svenska Nederlands
Nederlands Español
Español Lietuvos
Lietuvos
Because your website plays such an essential role in acquiring new customers in today’s market, you might be concerned about a popular term in the SEO industry called “thin content.” While the name itself is quite revealing, more subtleties are hiding behind it. Because of that, in today’s post, we’ll define what thin content means and how it works.
In SEO, thin content is broadly defined as website content that does not provide value to visitors. Such can be short, shallow, non-original, scraped, duplicate, doorway, or low-quality affiliate content. As a general rule, thin content doesn’t rank well in Google Search, as Google dislikes it.
Essentially, any content that does not add value to the searcher can be considered thin, both in the word’s literal and figurative senses. On one end, thin content means that there simply isn’t enough text on your page to satisfy the searcher. On the other hand, it also means that your pages don’t have high-quality enough content to meet the searcher’s needs.
Thin content is an official issue that appears in Google Search Console if it affects your website. However, if some of your pages consistently offer low-quality content, they can also get “shadowbanned” in a way – without any visible warnings from Google. When experiencing long periods of no ranking improvements even though you’re continuously optimizing your site, the reason can be thin and low-quality content.
It’s easier for more experienced SEOs to detect and improve pages that are suffering from the issue. But as a new SEO learner, you might have a hard time judging what exactly to improve. Because of that, below we’ve outlined thirteen factors you can address to fix your thin content or avoid a penalty.
What is thin content?
As we established, thin content is generally content that does not provide value to users. In other words, this means that the quantity and quality of your page’s content aren’t satisfactory. As a general rule, to quickly spot thin content, remember these types of page content below.
6 common types of thin content:
Website content that lacks depth or usefulness
Just because a page has a lot of content doesn’t make it good. Similarly, just because a page has some in-depth information doesn’t mean it deserves to rank high. High-quality content that deserves to rank also answers all questions and addresses all doubts the user might have. Namely, pages aren’t thin when they contain thorough content that matches (and potentially surpasses) the user’s needs.
Duplicate or repetitive website content
Duplicate or repetitive content is a strong signal for lower-quality content that falls under “thin content.” The website content on an individual page might be redundant, or several pages on your site might have duplicate content.
For example, if you have a 2000-word long article that repeats the same information, it can still be considered thin. That’s because it doesn’t provide more value as users read for longer.
Similarly, when many of your pages contain the same or very similar information, both Google and the end-users get confused about which page is the original source of information.
Pages with syndicated or scraped content
Outright stealing content is a big no-no when it comes to SEO. That’s because scraped and syndicated content doesn’t provide more value to users than the source. For that reason, Google sees no purpose in showing such pages to the user. Additionally, repeatedly taking content from other websites can lower your trust and prevent you from building relationships with content creators. In turn, this can be terrible for your website’s long-term success.
Doorway or low-quality affiliate pages
Doorway pages and low-quality affiliate pages are websites that essentially try to hide or manipulate the user. They hide, cloak, or redirect website content with the goal of ranking higher up in Google. All of this manipulation happens so that the user gets to believe they have landed on a “good enough” search result. Such could be websites that show only some content to search engines or outright redirect the user to another website to collect an affiliate commission. Such practices are a big no-no for Google, as the intention behind them is misleading and malicious.
These “scam pages” aren’t what they used to be since Google’s algorithms are much more advanced. They also aren’t as common; however, you can occasionally still see some examples. For instance, in 2020 and 2021, Google fought several fake Danish websites that quickly gained rankings and tried to abuse a Bitcoin scam.
Thin content on category, tag, or author pages
Category, tag, or author pages are some of the most common instances of thin content. That’s because if your website has been running for some time, you likely have leftovers from previous work. For example, websites with active blogs that allow guest posting at scale often have very shallow author pages. Or maybe you’ve created a ton of unique blog tag pages, making your website structure a puzzle for search engines to solve. Similarly, as the stock in any eCommerce store evolves, the website is often left with dozens (if not hundreds) of empty category or product pages.
To handle pages like this, it’s always best to review your website’s pages periodically. Running a website scan (or checking the “Coverage” tab in Google Search Console) can help you find thin pages that can become more problematic over time. From there, you can revive the pages, remove and redirect them, or simply no-index them.
Overwhelming pages with many ads or popups
Pages with shallow content predominantly filled with ads and popups can often be considered thin content by Google. The content is not entirely satisfactory to the end-user, and the intrusive ads and popups further worsen the user experience. In some scenarios, depending on the technology used, Google can also get blocked by popups. When that happens, it renders only the popup as the main content of the page, which can negatively impact that page’s rankings.
Why is thin content bad for SEO?
Naturally, when you provide a suboptimal user experience, your rankings are going to suffer. Thin content plays a major role in this equation. It immediately pushes your readers to look for another resource to get their search needs met.
In general, thin content is perceived as not valuable and hurts your SEO performance. Pages with thin content bring your overall website authority down, cannibalize keywords, or get deindexed. Solving thin content issues by removing, improving, or consolidating pages can improve your SEO rankings.
Thin content can potentially bring your overall website authority down in the eyes of your consumers. In turn, this can negatively impact your brand in both the short and long term. Dissatisfied prospects are less likely to return to your website. Conversely, they are more likely to actively avoid doing business with you.
In some instances, shallow content on thin pages can also cause keyword cannibalization, where important pages get deindexed if they overlap with the thinner pages. This issue should not present itself too often because your shallow content has a lower chance of ranking. However, it can potentially confuse Google and cause temporary fluctuations in your rankings.
When trying to solve the issue, the best way to handle thin pages is to determine whether you can use them for anything. Those that can potentially bring you some benefits are best for a touch-up and improvement. For example, truly worthless pages like old blog tags can easily be removed and redirected.
In a way, doing this tells Google that your website is well maintained – rather than piling up broken 404 links and wasting your crawl budget. Lastly, suppose some of your thin pages overlap topic-wise. In that case, you can also combine them into a single resource to ultimately improve the page’s quality.
How to identify thin content?
Identifying thin content can be done manually but requires a lot of time and effort in managing such a project. Because of that, there are faster ways to check and identify thin content on your website, using multiple tools. We’ll look at the five steps to uncover the majority of thin content and duplicate content issues.
5 ways to find and identify thin content:
1. Analyze thin pages in Google Search Console
Google Search Console is one of the best tools with which you can identify thin content. That’s because it gives you good, intuitive data – but also because it shows you exactly how Google sees your website, which is what most of us care about.
A great indicator of thin content is blog content or landing pages that do not get any search traffic, although they normally should. That is, you need to look for posts and pages to which you have already given enough time to rank accurately. If you find any pages that are supposed to rank but aren’t, this can indicate that the content is thin – or at least subpar.
Additionally, explore the “Manual Actions” tab to find if you aren’t already penalized in some way. Although the name of the tool refers to the manual penalties Google’s review team used to issue, to my understanding, most of the modern penalties that appear in there are algorithmic.
Lastly, the Coverage tool reveals excellent information about how Google understands and handles your pages too. Once in it, explore the “Excluded” tab to see all pages that Google decided not to feature in their index – and why. Some of the best reports to explore are:
- Crawled – currently not indexed
- Duplicate without user-selected canonical
- Duplicate, submitted URL not selected as canonical
- Duplicate, Google chose different canonical than user
2. Check for URL parameters causing duplicates
Since you’re already in Google Search Console, let’s handle a potentially big issue, especially for eCommerce stores.
In Google Search Console, navigate to the Settings options at the bottom of the left-hand sidebar. Once there, click on “Open report” under Crawl Stats. In your crawl stats, scroll down to “Crawl requests breakdown” and click on “OK (200)” under the “By response” tab.
Doing this will pull a list of all valid URLs crawled by Google, together with a timestamp. Here, you’re looking for URLs that contain parameters that do not normally modify the page’s contents. Here’s an example of a parameter that we don’t even use yet still somehow gets crawled by Google (bots and spam websites can cause those).

Once you’ve identified the URL parameters (modifiers), you can use the “URL Parameters” tool to handle them. It can be found under “Legacy tools and reports” in the left-hand sidebar in Google Search Console. To better understand how to configure your URL parameters, I recommend this explanation for consolidating duplicate URLs and this guide by Seer Interactive.
3. Set up your primary keywords in a rank tracker
Setting up a rank tracker can quickly alert you of problems with your content. Doing this can help you find both issues related to thin content or keyword cannibalization. With such alerts, you can quickly see if a page drops in rankings or gets completely deindexed.
For example, some time ago, with the help of our rank tracker, I was quickly able to find and fix a critical issue with one of our articles. At the time, Google decided to index one of our posts in German for the English keywords. Because we already had an English version, that original post dropped its rankings from the Top 3 to the last page for its main keyword.
As you can see, monitoring and quickly fixing such issues can be critical if Google’s algorithm makes a mistake, and this is what a keyword management tool can help you identify.
4. Find duplicating titles and meta descriptions
Using a website crawler tool like Screaming Frog, you can quickly check whether any of your page title tags or meta descriptions are duplicates. Having original page titles and meta descriptions matters because otherwise, you can confuse Google and your readers. Having two pages that look identical can also make it harder to navigate your website’s content.
Although Screaming Frog can be complicated without extensive technical understanding, it comes with a free version that lets you fetch 500 of your website’s pages. Here, all you need to do is enter your website, wait for the scan to complete, and examine the following tabs for duplicate titles and meta descriptions:
- Title 1
- Title 1 Length
- Meta Description 1
- Meta Description 1 Length
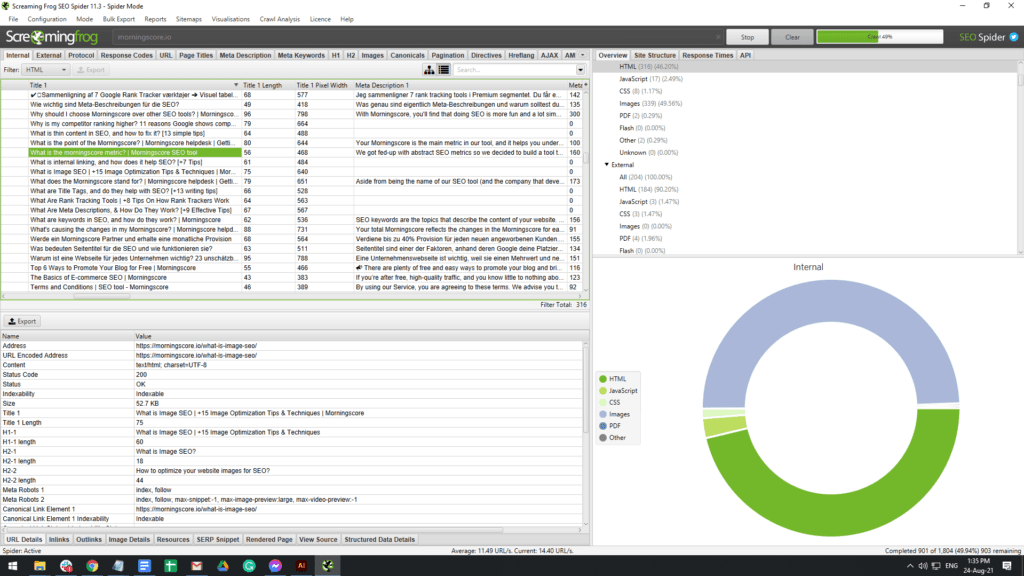
5. Use a website crawler to find duplicate content
The last critical step in identifying thin and duplicate content is to actually crawl your website with a tool that can compare the content itself. Again, powerful website crawler tools like Screaming Frog have many ways of troubleshooting problems with your website. To find duplicate content across different pages, I recommend reading this detailed guide by Screaming Frog themselves.
Alternatively, there are simpler tools if you already suspect several of your pages have thin content. In such cases, you can use a plagiarism checker to test and confirm your hypothesis. Free tools like CopyScape and Siteliner can help you get that done quickly.
How to fix thin content?
As we established, thin content means low-value content. Because of that, when looking to avoid any type of thin content penalty, your goal is to make your pages stand out in both the user’s and Google’s eyes in a positive way.
In general, depending on the type of content you offer, this means adding, for example, more in-depth content that users find helpful, more visuals, expert comments that back up your claims, original research, etc. Now let’s look at specific tactics you can implement to produce awesome content that users love – thus avoiding thin content.
13 ways to fix and avoid thin content:
1. Show that you’re a real company or brand
Many of the recent SEO issues have to do with a lack of trust. Google is aware that many unqualified people or outright scammers make websites to squeeze money out of people. Fortunately, Google is actively fighting against spammers and scammers on the internet with continuous algorithm updates over the years. Similarly, this represents how users feel about their digital behavior, and in particular, purchases.
No one wants to be scammed, and people look for signals of trust on the website they land on. This tells them whether they are buying from a real company or someone is trying to find a sneaky way into their credit card. Ultimately, Google wants to represent how valuable users find content – if users trust this source the most, the content should rank well.
Because of that, your goal with your website is to show that you’re a real person behind a real company that values customer satisfaction. You can do that by both showing your company information on your website, having a well-written and optimized “About” page, and showcasing some of your work.
Ultimately, you also want mentions of your work and expertise in other media outlets – as Google considers them more objective than a self-serving description of yourself. However, do not buy mentions and links or participate in link schemes, as this can hurt your reputation with Google.
2. Use a clean, modern, usable website design
The design and colors of your website have a direct effect on the psychology of your buyers. Colors cause certain reactions and expectations in your visitors, some of which can make the user perceive your company as less trustworthy. The same can be said about outdated layouts that feature bad formatting. For example, websites that look like those from the early 2000s can be seen as spam by your visitors. In such a case, at best, your conversion rates will be lower than they should be, and in worst-case scenarios, this can destroy all trust with new potential customers.
3. Limit the number of ads and affiliate links
Another factor affecting your visitors’ trust can be showing too many ads or affiliate links. After all, if all you try to do is sell, people won’t like that. Additionally, Google has explicitly said that unhelpful affiliate content falls under “thin content.” Lastly, loading too many external scripts from ad networks can drastically slow down your website and thus lower your rankings even if your content is not thin.
4. Avoid shady formatting like hiding or cloaking links
In order to build trust and relationships with your potential customers, you should steer clear of shady practices that try to scam users. To name a few, such can be cloaking your links or formatting links to be the same color as the website’s background. Transparent and open companies earn the visitor’s trust – and have much higher chances of ranking well in Google.
5. Always write original content that adds value
Firstly, original content is received better by your users. Additionally, it tells Google your content is in no way taken from somewhere else.
Original content can have many forms. Essentially, ask yourself whether your content adds something new to the subject. You don’t have to always come up with entirely new information on the topic – simply presenting it better, making it more helpful, and connecting the dots in a new way can be enough to make your content original enough.
Some topics simply have too much information written on them already. Meanwhile, others have little to no information – especially information offered in an appealing format. These topics are a goldmine for you to optimize around – since you’re almost certain you can rank well for them.
Lastly, from personal tests, I’ve seen that original content also gets indexed by Google faster and easier – even on new websites.
6. Avoid thin content by writing in-depth articles
Your goal is always to try to explain the subject in-depth. To do that, try to predict what following questions the user might have after searching for what you wrote. Your goal here is to be like Netflix, where every episode ends with a cliffhanger and makes you watch more. Similarly, your content needs to be presented in a way that makes your reader read more.
For example, take this article called “why are my competitors ranking higher.” Here, our goal is to give a quick answer so that it satisfies the user quickly. However, doing just that means the page will have thin content – and will not rank in Google. Therefore, below the initial response, we decided to list and explain each individual problem. If you understand SEO, you can find each of these points scattered across the web in different formats. However, from our research, we saw that no one has combined and explained them like that – which was a great incentive for us to do so.
Lastly, note down the Search Intent behind each topic. If a user is searching for “how long do dolphins get,” they likely wouldn’t click on content about “how long can dolphins swim for.” Therefore, make sure you keep your content on point. For example, in this specific instance, these could be sub-topics like “average dolphin length at different ages,” “dolphin length by breed,” and so on. This is also doable for landing pages – but more on that in the points below.
7. Paraphrase content but never plagiarize it
Understandably, sometimes you want to use content present on other pages. Whenever that happens, ensure that you’re paraphrasing the content wherever possible. Google algorithms look closely at how duplicate content is treated – and it isn’t happy about plagiarized text when it finds it.
If that text is a quote from someone else’s website, which cannot be paraphrased, ensure that it isn’t a large portion of your content. How much is too much? Although there’s no one number, we’d recommend keeping it under 10% as a rule of thumb. Think of it this way – the more content you copy from another website, the weaker the reason for ranking you higher is.
Instead, breaking down content from another page, explaining it better or simpler, and adding something new to the subject, is a perfectly acceptable reason for you to rank higher.
Lastly, if you really need to use a lot of content from other websites, give it a spin by adding it as images instead of plain text. Underneath each image, you’ll have a chance to paraphrase that content through your own words and explain what the original author means.
8. Use link sources to the original publisher
One way of ensuring you give Google the right signals when using others’ content is to follow effective resource linking strategies. Here, you can either use contextual links (e.g., “this website reports that…”) or adhere to a certain citation standard (and, e.g., link out from the word “Source”) depending on the style of the content.
External links are a great signal for Google because they often prove that your content has ground. Essentially, you’re signaling that what you’re writing is proven, and you didn’t just make it up (especially true in some industries like health and finances).
To put things into perspective, imagine that you’re writing an article on “Top 10 Healthiest Fruits.” You have tons of opportunities to link to other sources for each item (i.e., fruits) on your list in such posts. For example, suppose that one of those items is “bananas.” In it, you mention that they contain a high amount of potassium, contain antioxidants, and have a high amount of fiber. Now simply link each of these claims to articles supporting (or denying) them from those specific words.
9. Write at least 1000 words on articles
Firstly, we need to establish that content length in itself isn’t necessarily what makes you rank higher. Google’s official statement does not feature a magic number you need to follow in order to avoid any thin content-related penalties. However, content length and page ranking correlate in that usually longer content is also better and more in-depth.
The single best way to avoid the thin content issue caused by having shallow pages is simply adding more in-depth content on the specific subject. There is no exact rule given by Google of how long your pages should be. However, the rule of thumb is that the more specific and in-depth your pages are, the more content you’re going to have, and thus it will be harder for someone else to outrank you in the long run. Additionally, the more helpful, in-depth content you feature, the higher your chances of remaining at the top.
Therefore, when writing articles, we recommend that you aim for around 1000 to 1300 words. Some more competitive pieces will require a lot more than that. However, this number can serve you as a benchmark that guides you toward how detailed you should write.
The one-thousand-word mark also makes sense when you think about the information you feature in your articles from a search intent perspective. That is, a regular, well-ranking blog post that perfectly matches the user’s search intent usually features 2-5 subheadings. If you break down each heading into smaller sections, you can see that each of them contains roughly 200-400 words – which is usually sufficient in covering that subject.
If you’re wondering what more you can write about your subject, the simple solution is to do more or better keyword research. Any expert in any one industry will always be able to write at least 1000 words on any subject. If you’re having a hard time, familiarize yourself better with the subject. Combined with a good understanding of search intent – i.e., when and what content to combine and split – you have a winning formula for avoiding thin content in the long run.
10. Write at least 700 words on landing pages
To avoid having thin content on important landing pages, make sure you’re adding enough in-depth content to them. When creating landing pages, first plan out what useful content you can add to them that aids visitors’ decision-making process. After that, examine how you can add that content to your pages. For example:
- List features or sub-features with original content for each of them
- Add a (comparison) table
- Add relevant FAQs to the product, feature, or service the page is about
- Embed a video demonstrating your product
- Feature dimensions and specs for the product or service
As a general rule, you should aim for at least 700 words on your important landing pages. Whenever a product is involved, the SEO competition rises since Google Search is a powerful channel for passively attracting customers. Even though less content doesn’t directly imply a thin content penalty, it is likely insufficient to get you ranked high at the top.
Because of that, even if you find yourself in a niche with fewer competitors, remember that there are always new websites popping up. While you might get a good rank in the short term, a competitor might outrank you in the long run.
11. Redirect shallow pages with no traffic
To avoid thin content pages, you should analyze your website and note down which pages don’t fit the criteria listed above. Once you have a list of which pages need to be addressed, you can make a priority list.
Do you have pages targeting important keywords? It’s likely worth revisiting the content there and upgrading it following the steps from above.
Have you identified any pages that serve no purpose? Be sure to remove these. However, don’t simply delete the page. Instead, once you remove it, add a 301 Redirect to it, pointing the URL to the next most relevant page. This will tell Google that the page has been removed, and it should offer the other one instead. Otherwise, when inspecting your site, Google will see a broken (404) page, informing it something isn’t right.
As you’ve seen by now, Google likes well-maintained websites. Having many 404 pages can be yet another reason for them not to promote you higher up in the search results.
Lastly, are there pages you’re unsure about? See if that page gets any traffic and ask yourself if it will be relevant a year from now. If the answer is no to both, feel free to remove it with the method explained above.
12. Redirect pages with duplicating content
Once you’ve done the analysis from above, you absolutely need to ensure you consolidate any duplicate URLs. Duplicate content is one of the most severe factors that Google considers thin content – whether taken from other websites or your own.
Even if Google doesn’t penalize your duplicating content, you might be preventing your own pages from ranking as high as they should. That’s because Google uses each page’s content to derive a meaning for what that page is about. Having several pages with duplicating content essentially confuses Google about which page is most relevant. This can cause the issue of keyword cannibalization. And in worse scenarios, your pages can get rapidly de-indexed, causing your rankings to drop.
Sometimes, however, you still want to keep a page alive because it has a particular purpose – even though it shouldn’t rank for anything. In those cases, you can either remove the page from Google’s index by changing its meta robots tag to “noindex.” Alternatively, you can add a canonical tag to it towards a more important page that’s supposed to rank in Google.
To give you an example of how easy it is for something like this to happen sometimes, I’ll share a story from my experience. A few years ago, I wrote a post on “push and pull marketing.” We saw that this post ranked high for our target keywords and decided to scale that strategy in other markets, too – i.e., Google Germany.
While the content was original enough in each language, a few months down the line, suddenly, our German post got indexed for the English phrase – and the English page got de-indexed. We lost the rankings on those keywords overnight – and I was suddenly tasked with fixing that.
13. Exclude URL parameters causing duplications
Most of the time, Google is pretty smart in understanding the structure of your website. However, sometimes things get tricky and confuse it into believing certain pages exist when they don’t. This often happens because of URL parameters used for tracking and not modifying the page’s contents (e.g., “fbclid=“).
However, once found, Google can still see them as “individual pages” containing duplicate content – when they aren’t really such.
Most commonly, URL parameters are denoted with a “?” (question mark symbol) before each parameter’s name in the URL of your website. In a similar fashion, the “=” (equals character) denotes that the following string is the value for that parameter. Although Google does a great job of catching them, it can sometimes miss them, believing they are unique URLs.
To avoid this becoming an issue, you can use the URL Parameters Tool in Google Search Console. Adding the parameter in the tool allows you to tell Google to ignore all URLs containing that string. Doing this can prevent thin content issues and ensure Google is rightfully spending your crawl budget on pages that matter. However, before doing so, as per Google’s guidelines for moving content, be careful not to exclude essential pages from their index.
When did thin content become an issue?
In the past, ranking on Google was much different. Simply re-using relevant content from other websites allowed you to appear at the top for important keywords. Naturally, Google wasn’t happy with that – because it affected their end-users. Such recycled content was often low-quality and didn’t offer anything new or useful to users looking to answer a question or solve a problem. This practice slowly spiraled out of control throughout the years, and SEOs would easily game the algorithm for their own or their client’s profit.
Google’s modern core updates aim to make search more relevant by rewarding high-quality websites that offer genuine value. These updates target pages with little content as well as duplicate, plagiarized (scraped) pages combined with keyword stuffing and user-generated spam content.
By now, you likely see a pattern – essentially, the goal is to avoid creating valueless pages with low-quality content. Now let’s take it a step further by looking at precisely what factors you should consider to avoid triggering Google’s quality filters. Below we’ve laid out how exactly you can prevent a thin content penalty.
Identifying & fixing thin content issues
Thin content is not an issue most websites need to worry about nowadays. That’s because modern marketing people, content writers, and SEOs alike understand that the demand for high-quality content has risen.
With countless authoritative websites competing in search, Google has propagated SEO practices that ultimately serve the end-user best. Therefore, if you’re following the latest best practices in SEO, it’s improbable you’ll end up with such an error.
Frequently Asked Questions
What is the minimum word count to avoid thin content in SEO?
There is no official magic number from Google, as thin content is about the value provided rather than just the length. However, a good rule of thumb is to aim for at least 1,000 words for blog posts and 700 words for important landing pages to ensure you cover a topic in-depth. Focus on satisfying the searcher’s intent and answering all their potential questions to avoid being flagged for low quality.
How do I find thin content issues in Google Search Console?
You can identify potential thin content by looking at the “Indexing” report (formerly Coverage) and checking for URLs listed under “Crawled – currently not indexed.” Additionally, you should check the “Manual Actions” tab to see if Google has issued a specific penalty. If you notice pages that should rank but get zero traffic, it is a strong signal that Google perceives the content as thin or subpar.
Is duplicate content always considered thin content?
In the eyes of Google, duplicate or scraped content is almost always viewed as thin because it does not provide new value to the user. When multiple pages on your site or across the web feature the same text, it confuses search engines and can lead to keyword cannibalization. To fix this, you should consolidate these pages using 301 redirects or use canonical tags to point to the original version.
Should I delete thin pages or use a noindex tag?
The best approach depends on whether the page serves a purpose for your visitors. If a page like a thin blog tag or an old category page is useless, you should remove it and use a 301 redirect to the most relevant alternative. If the page is necessary for user navigation but doesn’t need to rank, changing the meta robots tag to “noindex” is an effective way to keep your site’s overall quality high in search results.
Can thin content on a few pages hurt my entire website’s ranking?
Yes, having a high volume of thin or low-quality content can lower your overall website authority. Google prefers well-maintained sites, and a collection of shallow pages can waste your crawl budget and signal that your site is not a trusted resource. Identifying what is thin content in SEO and fixing those pages by improving, removing, or consolidating them can often lead to a site-wide boost in performance.
